scrapy shell -s USER_AGENT="Browser AGENT" URL
源URL
https://www.zhihu.com/api/v4/answers/640764591/rewarders?include=data%5B*%5D.answer_count%2Carticles_count%2Cfollower_count%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed&offset=0&limit=10偏移量 = 从哪条开始
限制 = 加载多少条 数据
分析网站URL请求的结构,是非常重要的。它会让我们清楚应该发送什么样的请求
重构 pipeline
假如一个 item 对应一个 pipeline,后续上百个或者更多的 item,岂不是需要发起上百次 db 连接,现在需要做的就是一个 pipeline / cursor,处理所有的 item。实际上在真正的开发中,有可能不同的 spider 或一个 spider 爬取的数据,我们需要存储到不同的 db 当中,这个时候可以根据不同的 db 建立 pipeline。
实现一个 pipeline 处理多个 item
在每个 item 中,定义 insert sql 语句,与需要 insert 的 tuple field,作为实例方法,返回出去
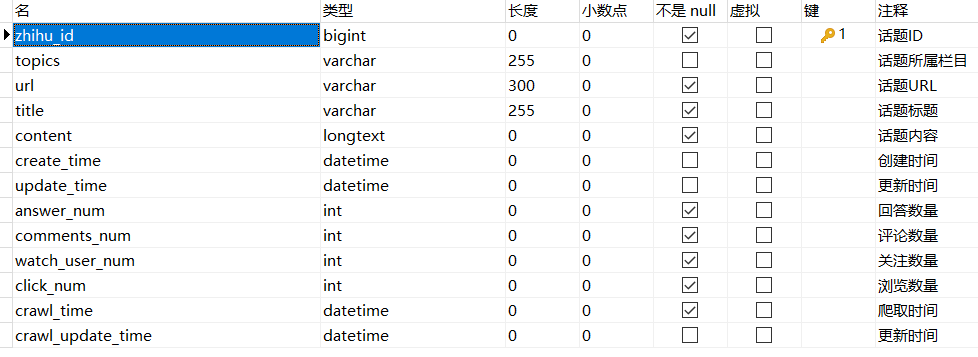
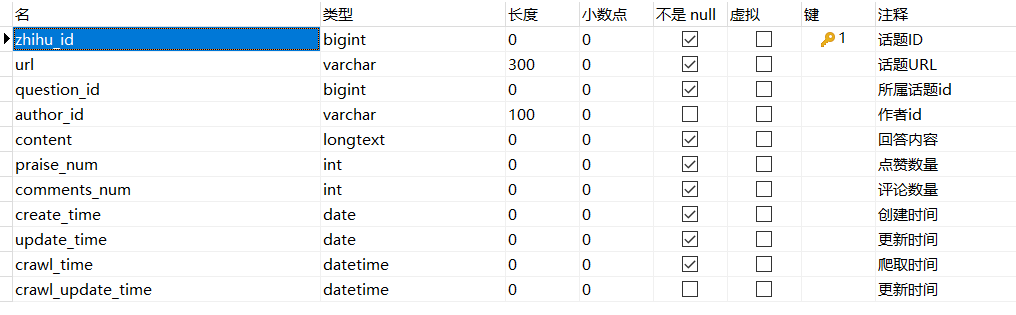
def get_insert_sql(self): """ 定义 insert_sql 语句,以及参数 """ insert_sql = ''' insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num, comments_num, watch_user_num, click_num, crawl_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ''' params = ( self.get('zhihu_id', 0), self.get('topics', ''), self.get('url', ''), self.get('title', ''), self.get('content', ''), self.get('answer_num', 0), self.get('comments_num', 0), self.get('watch_user_num', 0), self.get('click_num', 0), self.get('crawl_time', '1970-01-01') ) return insert_sql, params重构 Twisted 类 -> do_insert 方法
def do_insert(self, cursor, item): """ cursor(游标)参数,是 Twisted.adbapi 模块,自动注入的 入库逻辑代码 根据不同的 item , 构建不同的 sql 语句,并插入到 db 中 """ # 不推荐的用法, 通用性不强 # if item.__class__.__name__ == 'JobBoleArticleItem': # 调用实例化对象 item 中的方法,获取 insert sql 语句,与 tuple field insert_sql, params = item.get_insert_sql() # 传入 sql 语句,以及对应的参数 cursor.execute(insert_sql, tuple(params)) return item



